 prometheus学习笔记
prometheus学习笔记
# prometheus相关实践
# docker部署prometheus和grafana
# 启动node-exporter
docker run -d -p 9100:9100 \
--name node-exporter \
--restart=always \
-v /data/apps/docker/node-exporter-data/proc:/host/proc:ro \
-v /data/apps/docker/node-exporter-data/sys:/host/sys:ro \
-v /data/apps/docker/node-exporter-data:/rootfs:ro \
prom/node-exporter
2
3
4
5
6
7
# 编写prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 192.168.0.104:9090
- job_name: node-exporter
static_configs:
- targets:
- 192.168.0.104:9100
- job_name: jenkins
scheme: http
metrics_path: prometheus
bearer_token: bearer_token
static_configs:
- targets:
- 192.168.57.242:8080
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 启动promethus
docker run -d \
--name prometheus \
--restart=always \
-u root \
-p 9090:9090 \
-v /data/apps/docker/prometheus-data/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/apps/docker/prometheus-data:/prometheus \
-v /data/apps/docker/prometheus-data/conf:/etc/prometheus/conf \
prom/prometheus --web.enable-lifecycle
2
3
4
5
6
7
8
9
# 启动grafana
docker run -d \
-p 3000:3000 \
--restart=always \
--name=grafana \
-u root \
-v /data/apps/docker/grafana-data:/var/lib/grafana \
grafana/grafana
2
3
4
5
6
7
grafana账号密码默认admin
# Metric指标
# 数据模型
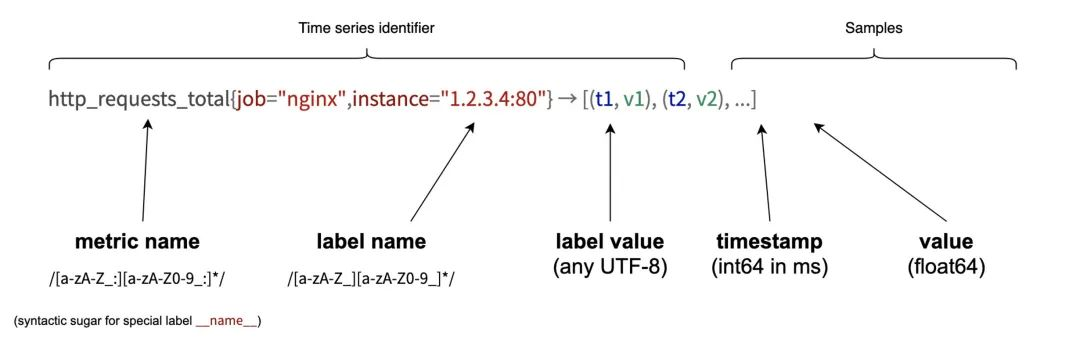
Prometheus 采集的所有指标都是以时间序列的形式进行存储,每一个时间序列有三部分组成:
- 指标名和指标标签集合:metric_name{<label1=v1>,<label2=v2>....},指标名:表示这个指标是监控哪一方面的状态,比如 http_request_total 表示:请求数量;指标标签,描述这个指标有哪些维度,比如 http_request_total 这个指标,有请求状态码 code = 200/400/500,请求方式:method = get/post 等,实际上指标名称实际上是以标签的形式保存,这个标签是name,即:name=。
- 时间戳:描述当前时间序列的时间,单位:毫秒。
- 样本值:当前监控指标的具体数值,比如 http_request_total 的值就是请求数是多少。
# 指标类型
- Counter 计数器
- Gauge 仪表盘
- Histogram 直方图
- Summary 摘要
# PromQL
PromQL 是 Prometheus 为我们提供的函数式的查询语言,查询表达式有四种类型:
- 字符串:只作为某些内置函数的参数出现
- 标量:单一的数字值,可以是函数参数,也可以是函数的返回结果
- 瞬时向量:某一时刻的时序数据
- 区间向量:某一时间区间内的时序数据集合
# 瞬时查询
直接通过指标名即可进行查询,查询结果是当前指标最新的时间序列,比如查询 Gc 累积消耗的时间:
# 直接查询
go_gc_duration_seconds_count
# 筛选
go_gc_duration_seconds_count{instance="127.0.0.1:9600"}
# 正则
go_gc_duration_seconds_count{instance=~"localhost.*"}
2
3
4
5
6
# 范围查询
范围查询的结果集就是区间向量,可以通过[]指定时间来做范围查询,查询 5 分钟内的 Gc 累积消耗时间:
# d:天,h:小时,m:分钟,ms:毫秒,s:秒,w:周,y:年
go_gc_duration_seconds_count{}[5m]
# 偏移
go_gc_duration_seconds_count{}[5m] offset 1d
2
3
4
# 内置函数
# rate
rate 函数可以用来求指标的平均变化速率
rate函数=时间区间前后两个点的差 / 时间范围
一般 rate 函数可以用来求某个时间区间内的请求速率,也就是我们常说的 QPS:
rate(demo_api_request_duration_seconds_count[1m])/60
但是 rate 函数只是算出来了某个时间区间内的平均速率,没办法反映突发变化,假设在一分钟的时间区间里,前 50 秒的请求量都是 0 到 10 左右,但是最后 10 秒的请求量暴增到 100 以上,这时候算出来的值可能无法很好的反映这个峰值变化。这个问题可以通过 irate 函数解决,irate 函数求出来的就是瞬时变化率。
# irate
irate = 时间区间内最后两个样本点的差 / 最后两个样本点的时间差
# 聚合函数:Sum() by() without()
# 将多个服务多个接口的请求聚合
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m]))
# 根据请求接口标签分组
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) by(path)
# 不根据接口路径分组
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) without(path)
2
3
4
5
6
7
8
# histogram_quantile
# 用来统计百分位数:第一个参数是百分位,第二个 histogram 指标,这样计算出来的就是中位数,即 P50
histogram_quantile(0.5,go_gc_pauses_seconds_total_bucket)
2
# 其他
# prometheus配置动态动态更新
- 启动时需带上参数
prometheus --config.file=/usr/local/etc/prometheus.yml --web.enable-lifecycle - 更新prometheus.yml配置
- 通过post的方式请求接口
curl -v --request POST 'http://localhost:9090/-/reload'
# 指标抓取和存储
Prometheus 对指标的抓取采取主动 Pull 的方式,即周期性的请求被监控服务暴露的 metrics 接口或者是 PushGateway,从而获取到 Metrics 指标,默认时间是 15s 抓取一次,配置项如下:
global:
scrape_interval: 15s
2
抓取到的指标会被以时间序列的形式保存在内存中,并且定时刷到磁盘上,默认是两个小时回刷一次。并且为了防止 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 也提供了类似 MySQL 中 binlog 一样的预写日志,当 Prometheus 崩溃重启时,会读这个预写日志来恢复数据。
# prometheus分位数坑点
Prometheus 不保存具体的指标数值的,他会帮你把指标放到具体的桶,但是他不会保存你指标的值,计算的分位数是一个预估的值,怎么预估呢?就是假设每个桶内的样本分布是均匀的,线性分布来计算的。
假设我们指定桶为:[]float64{0,2.5,5,7.5,10}
则 P50,其实就是算排在第50%位置的样本值,假设刚刚所有的数据都落在了第一个桶,那么他在计算的时候就会假定这个50%值在第一个桶的中点,他就会假定这个数就是 0.5*2.5,P99 就是第一个桶的 99%的位置,他就会假定这个数就是 0.99*2.5。
导致这个误差较大的原因就是我们的 bucket 设置的不合理。